
By Can Gencer
VP R&D
Can is one of the founding members of the Hazelcast Jet team and is currently the engineering team lead. Prior to joining Hazelcast, he worked as a software development consultant to some of the world’s leading investment banks. He has deep interest in distributed systems, stream processing and building high-throughput, low-latency data pipelines. He is also a polyglot programmer with expertise in Java, Python, C# and functional programming.
View all blogs by the authorFeb 9, 2017
Introducing Hazelcast Jet 0.3
I am happy to announce that after more than one year of hard work, we are ready to release the first public version of Hazelcast Jet – a new open source distributed data processing engine by Hazelcast. Jet is the first new product by Hazelcast, after our well known in-memory data grid (IMDG) offering, and combines advanced distributed data processing capabilities with in-memory storage. ` At its core Jet uses Directed Acylic Graphs (DAG) to model data flow, where each vertex describes a step in the computation. The vertex’s computation is executed in parallel by several instances of processors. Since Jet is a distributed engine, the processors have access to the computing resources of several machines at once. Vertices are connected by edges, which determine how data is routed from the upstream vertex’s processors to the downstream processors.
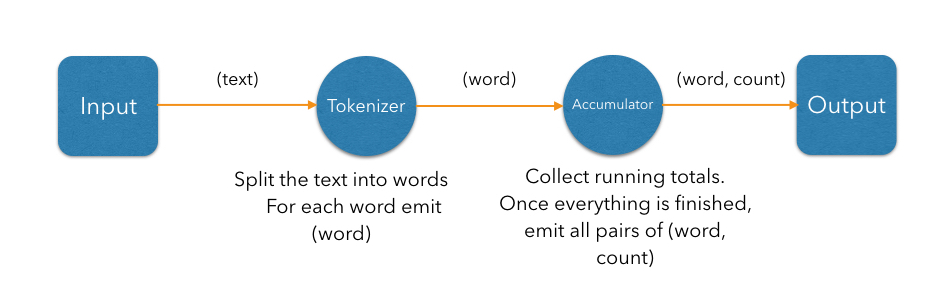
For example, an application which counts the number of times each word occurs in a text can be modeled as the following graph:
Each of these steps will be executed in parallel, with several processors per vertex running across multiple nodes. Edges are implemented using concurrent queues between processor instances. They buffer data produced by the source processor and then let the destination processor drain it.
To give you a taste of the DAG API, this is the code that builds a word count DAG very similar to the one in the above diagram:
JetInstance jet = Jet.newJetInstance();
IStreamMap<Integer, String> lines = jet.getMap("lines");
lines.put(0, "It was the best of times,");
lines.put(1, "It was the worst of times,");
...
DAG dag = new DAG();
Vertex source = dag.newVertex("source", readMap("lines"));
Vertex tokenizer = dag.newVertex("tokenizer",
flatMap((String line) ->
traverseArray(line.toLowerCase().split("\\W+"))
.filter(word -> !word.isEmpty()))
);
Vertex accumulator = dag.newVertex("accumulator",
groupAndAccumulate(() -> 0L, (count, x) -> count + 1)
);
Vertex combiner = dag.newVertex("combiner", groupAndAccumulate(
Entry<String, Long>::getKey,
() -> 0L,
(Long count, Entry<String, Long> wordAndCount) ->
count + wordAndCount.getValue())
);
Vertex sink = dag.newVertex("sink", writeMap("counts"));
dag.edge(between(source, tokenizer))
.edge(between(tokenizer, accumulator)
.partitioned(wholeItem(), HASH_CODE))
.edge(between(accumulator, combiner)
.distributed()
.partitioned(entryKey()))
.edge(between(combiner, sink));
jet.newJob(dag).execute().get();
High performance is one of the main goals of Jet and is achieved through the use of cooperative multithreading, which are a variation on green threads. This means that, instead of letting the OS schedule our work, Jet runs everything on just as many threads as there are available CPU cores. The basic processing unit, which is called a tasklet, cooperates with the execution engine by doing a little work each time it is called, then yielding back. Since Jet uses bounded concurrent queues with smart batching, this work pattern comes naturally: each tasklet call processes the data that’s ready in the queue. The concurrent queues used are also completely wait-free, which allows data to propagate through the graph with extremely low overheads.
Jet has close integration with Hazelcast IMDG, and builds upon its clustering, discovery, networking and serialization features. Those already familiar with Hazelcast can use the rich cluster setup and discovery capabilities with Jet as well. Jet also has a tight integration with Hazelcast distributed data structures: you can create distributed data structures on Jet instances themselves, and also make use of partition locality to perform reduction operations locally, then transmit just the reduced dataset over the network, then in the final step combine the partial results from each member.
Jet also adds distributed java.util.stream support to Hazelcast data structures, starting with IMap and IList. Given an IMap which contains a line of some text per entry, a simple word count can be implemented as follows:
JetInstance jet = Jet.newJetInstance();
IStreamMap<Integer, String> lines = jet.getMap("lines");
lines.put(0, "It was the best of times,");
lines.put(1, "It was the worst of times,");
Pattern pattern = Pattern.compile("\\W+");
IMap<String, Long> counts = lines
.stream()
.flatMap(m -> Stream.of(pattern.split(m.getValue().toLowerCase())))
.collect(toIMap(w -> w, w -> 1L, (left, right) -> left + right));
The resulting counts will then be available in the returned IMap instance for querying.
Jet can be used for both stream and batch processing – with more streaming features to be released in the upcoming releases. Currently it offers connectors for Hazelcast IMDG and prototypes for HDFS and Kafka which are under active development.
We will be exploring various aspects of Jet in more detail in the coming weeks in future blog posts. Meanwhile, feel free to browse through the reference manual and run the code samples on GitHub.