
Distinguished Engineer
Ensar’s primary areas of interest are distributed data, replication, consistency, and storage. He has more than seven years of hands-on expertise in designing, developing, and testing distributed algorithms, with solid experience in concurrency. He has authored a number of articles on distributed data and stream processing, and is a frequent speaker at industry conferences on topics such as replication and distributed systems. Several of his talks can be found on YouTube, including Replication Distilled, Distributed Systems for Mere Mortals, and Replication in the Wild. Ensar is a Ph.D. candidate in computer science at Bilkent University in Ankara, Turkey.
View all blogs by the authorMay 21, 2018
Subscribe to the blogHazelcast Jet 0.6: Dynamic scale out for streaming jobs
In Hazelcast Jet 0.5, we introduced fault tolerance for streaming computations. Hazelcast Jet periodically takes snapshots of the state of a running job and stores these snapshots in Hazelcast IMaps. In case of a failure, the job is restarted from the last successful snapshot. Hazelcast Jet 0.6 uses the same snapshotting mechanism to enable dynamic scaling of streaming jobs. We added a new method to the job interface: restart(). You can scale out your running jobs easily by adding new Hazelcast Jet nodes into your cluster and calling the new restart method. When Job.restart() is called, the ongoing execution of the job is stopped and a brand new execution is scheduled for the new cluster topology. If snapshotting is enabled for the job, then it is restarted from the last successful snapshot.
Let’s walk through the following code sample to see how the new method is used. We first submit a job to a 2 node Hazelcast Jet cluster. We also set the processing guarantee for our job, so Hazelcast Jet is going to take snapshots. Then, while the job is running, we start a new Hazelcast Jet node and call the restart() method. After this point, the job restarts from the last snapshot and runs on 3 nodes.
JetInstance instance1 = Jet.newJetInstance(); JetInstance instance2 = Jet.newJetInstance(); // build the pipeline by adding computation stages Pipeline pipeline = Pipeline.create(); // configure the job JobConfig jobConfig = new JobConfig(); jobConfig.setProcessingGuarantee(EXACTLY_ONCE); jobConfig.setSnapshotIntervalMillis(2000); Job job = instance1.newJob(pipeline, jobConfig); // just wait until the job starts and takes a couple of snapshots Thread.sleep(10000); // add a new node to the cluster JetInstance instance3 = Jet.newJetInstance(); // scale up the job job.restart();
This new feature greatly simplifies running streaming jobs with dynamic workloads. If you are curious about the secrets behind this simple looking trick, just keep reading…
Streaming applications contain stateless and stateful processors. A stateless processor processes each input item solely based on the information present on that item. On the contrary, stateful processors maintain internal state between firings of input items and use it while producing output items. Processor state is generally partitioned by a user-specified key and separate state objects are maintained for each key instance, in which case the processor is called partitioned stateful. Both stateless and partitioned stateful processors are amenable to data parallelism. For instance, we can create multiple instances of a stateless processor and distribute input items among its instances. We can process a data item in any instance of a stateless processor. However, it is a bit trickier to apply data parallelism to partitioned stateful processors. We need to ensure that all input items that belong to the same key go to the same processor instance, so that computation state is maintained correctly. For this reason, we create a mapping between keys and processor instances which keep local state. In addition, changing the degree of data parallelism for stateful processors, either because of a failure or scale out, is challenging. We need to be able to distribute and restore local processor state. Behind the scenes, Hazelcast IMDG’s data distribution capabilities help Hazelcast Jet to apply data parallelism on stateful computations and manage snapshot data in dynamic cluster topologies. Let’s explore it in more detail.
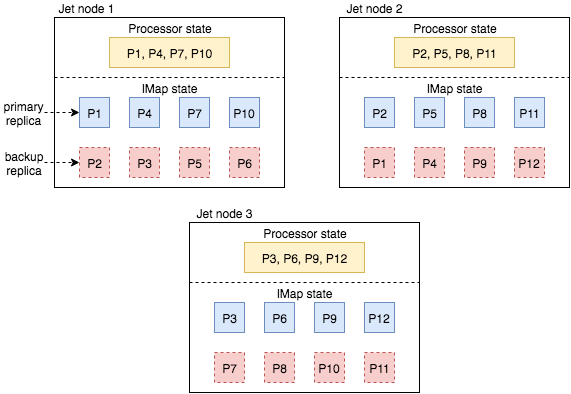
Hazelcast IMDG divides the key space into partitions (i.e., shards) and maps each key to a single partition. By default, there are 271 partitions. For each partition, Hazelcast IMDG creates multiple replicas, and assigns one replica as primary and other replicas as backups.
Consider the scenario where we have a cluster of 3 Hazelcast Jet nodes and 12 partitions, as shown in Figure 1. Primary replicas and backup replicas are shown respectively with solid blue boxes and dashed red boxes. For instance, 1st node keeps the primary replicas for partitions 1, 4, 7, and 10. In addition, it keeps backup replicas for partitions 2, 3, 5, and 6, whose primary replicas are assigned to 2nd and 3rd nodes.
In this scenario, we run a stateful processor which has local parallelism of 1 and a distributed partitioned inbound edge. Hazelcast Jet relies on Hazelcast IMDG partitioning schema to run this processor and store its snapshot data. For instance, if a data item sent by the upstream processor is mapped to one of the partitions 1, 4, 7, and 10, it is forwarded to the processor instance in 1st node. The same idea also applies to 2nd and the 3rd nodes. Each processor instance maintains its own internal state.
As described in the Hazelcast Jet docs, when a processor instance receives a snapshot barrier from its input streams, it puts its internal state objects into the Hazelcast IMap which is created for the current snapshot. Figure 2 demonstrates how state objects of the first processor instance are placed into the partition replicas of the snapshot IMap. As 1st node keeps the primary replicas for partitions 1, 4, 7, and 10, it keeps a copy of the state objects in the snapshot. Additionally, backup copies of these state objects are distributed to 2nd and the 3rd nodes.
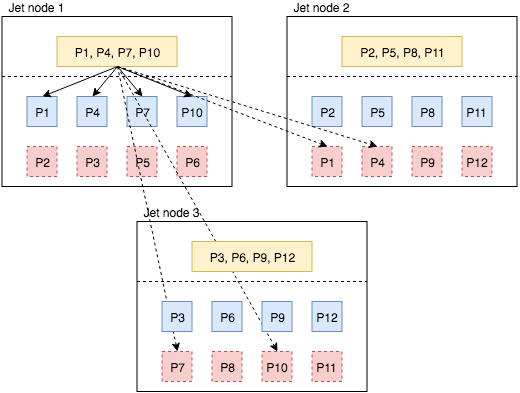
Let’s see how we make use of these partition replicas to recover processor state in case of topological changes. In Figure 3, we add a new Hazelcast Jet node to the cluster. Hazelcast IMDG rebalances the partitions and assigns some partition replicas to the new node. It uses the consistent hashing algorithm to move minimum amount of data between the nodes while rebalancing. In our scenario, the new node receives one primary replica and one backup replica from each existing Hazelcast Jet node. For instance, it takes primary replica of partition 1 and backup replica of partition 2 from 1st node. After partition rebalancing is done, the job is restarted and processor states are initialized from local replicas of the snapshot.
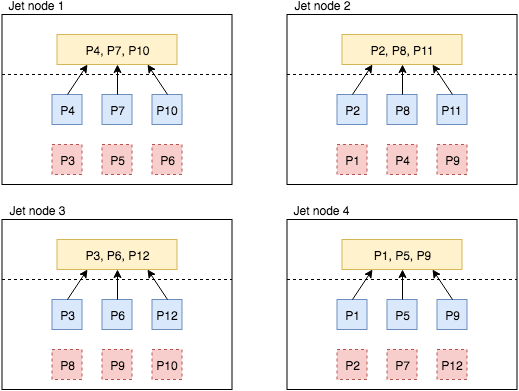
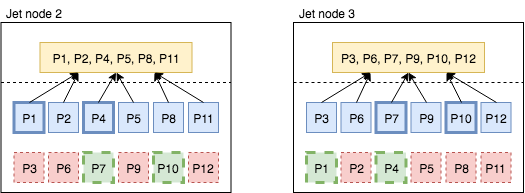
Finally, Figure 4 displays how Hazelcast Jet recovers from the failure of 1st node. Before the failure, 2nd and 3rd nodes were keeping the backup replicas for the partitions assigned to the 1st node. After the failure, 2nd node promotes partitions 1 and 4 from backup to primary. Similarly, 3rd node promote partitions 7 and 10. Since these promoted partitions lack a backup replica, the nodes create new backup replicas for each other, as shown with the bold-dashed green boxes. After this point, processor states are restored from local primary partition replicas.
Recap
Hazelcast Jet 0.6 extends its snapshotting mechanism to offer dynamic scale out capability for streaming jobs. In this blog post, we took a deeper look into how snapshot data is distributed and restored under the hood. You can check out the release notes and documentation to learn more about Hazelcast Jet.