
Bagri: The Document DB on Hazelcast IMDG
Q: What is your primary task when you start a new project?
A: To choose the right set of tools for the job, I believe.
This is the story about how I had to “choose the right tool” and how that lead me to build Bagri, the document DB.
At one time, I decided to build my own XML database because there were no suitable solutions on the market at that time. RDBMS extensions like Oracle XML DB, DB2 XML were quite limited and had no full XQuery support. Native XML DBs like BaseX, eXist-db were very good in XML processing but had restrictions in scalability and performance. MarkLogic – yes, that was the good one, had all basic functionality that I need, but – “bloody expensive”. So, I decided to start with a small prototype, just to see how easily could I get along.
My job speciality at that time was around Distributed Caches. So, the basic architecture of the future prototype was clear; take the incoming XML document, parse it and store all unique XML paths in a ‘model’ dictionary and all relevant data in ‘data’ cache. The cached ‘model’ would be accessible from any processing node, so a replicated cache made the most sense I was thinking. The document’s data should be distributed between system nodes where every node can process it’s own set of documents in parallel. Therefore a distributed cache with data partitioned by each document’s key would be the right choice. Then I would choose some relevant XQuery processor which could parse XQuery requests, using the parsed XPaths, converting them to set of queries against the distributed cache, and return the matching XML documents.
This was the first prototype. I did it in a couple of month and found it performed well enough, with initial throughput numbers around 1,000 requests per sec with an average request processing time around 10 – 20 ms. That said I decided to go on and start a real database project from the prototype that I had built.
This was how I had to choose the right toolset for my job. The initial prototype was built on a Coherence cache– a tool I use at my regular job and I knew the best. Building an open source project on top of Coherence, however, sounded a bit ridiculous. Nearly at the same time the 10-years old JCache API (JSR-107) got new attention and Oracle had announced to finalize it ASAP. So I took the decision to build my database on another distributed caching solution and later unify all communication with an underlying cache via the JCache API.
I already had experience working with Ehcache and Gemfire (and wasn’t too happy with them, I still remember the hours I spent investigating communication issues in the JGroups protocol). The GridGain project was not yet open source, so I had to choose between Hazelcast and Infinispan. Anyways, the first deep look that took into Infinispan showed that it handled putAll operations sequentially, one by one :(. This was not acceptable and so I choose Hazelcast IMDG.
Now the story about the toolset itself…
The first question I had in my mind: what’s the feature set my database should provide? Having quite a long experience with various RDBMS solutions and working in the banking area the curated list was:
- The solution must satisfy enterprise level requirements by transparently providing fault tolerance and high availability mechanisms.
- The solution must provide ACID transactional guarantees; apart from changes on a single document which are natively atomic, the system must guarantee ACID in operations on multiple documents.
- The solution must be able to run many databases (schemas) at the same time; every database can be deployed and used independently of all others.
- It must be possible to manage and monitor schemas and their resources from one central location.
- The system must be able to control user access to schemas and their documents.
- The system must provide some way to control document processing logic on server side by means of triggers and stored procedures.
- It must be possible to specify indexes for faster access on specific XPaths; indexes can be unique or not, ordered or not, case-sensitive or not, etc…
- The system must be accessible via a standard interface like JDBC in RDBMS world; query language must also be standard and allow to perform any ETL tasks effectively.
- It must be possible to process not only XML documents, but also other formats: JSON for instance; thus, the solution must allow registration of custom data format parsers and handlers.
I was not so confident with other NoSQL solutions at the time. Otherwise the list above could’ve been shorter, however, maybe this wasn’t not so bad?
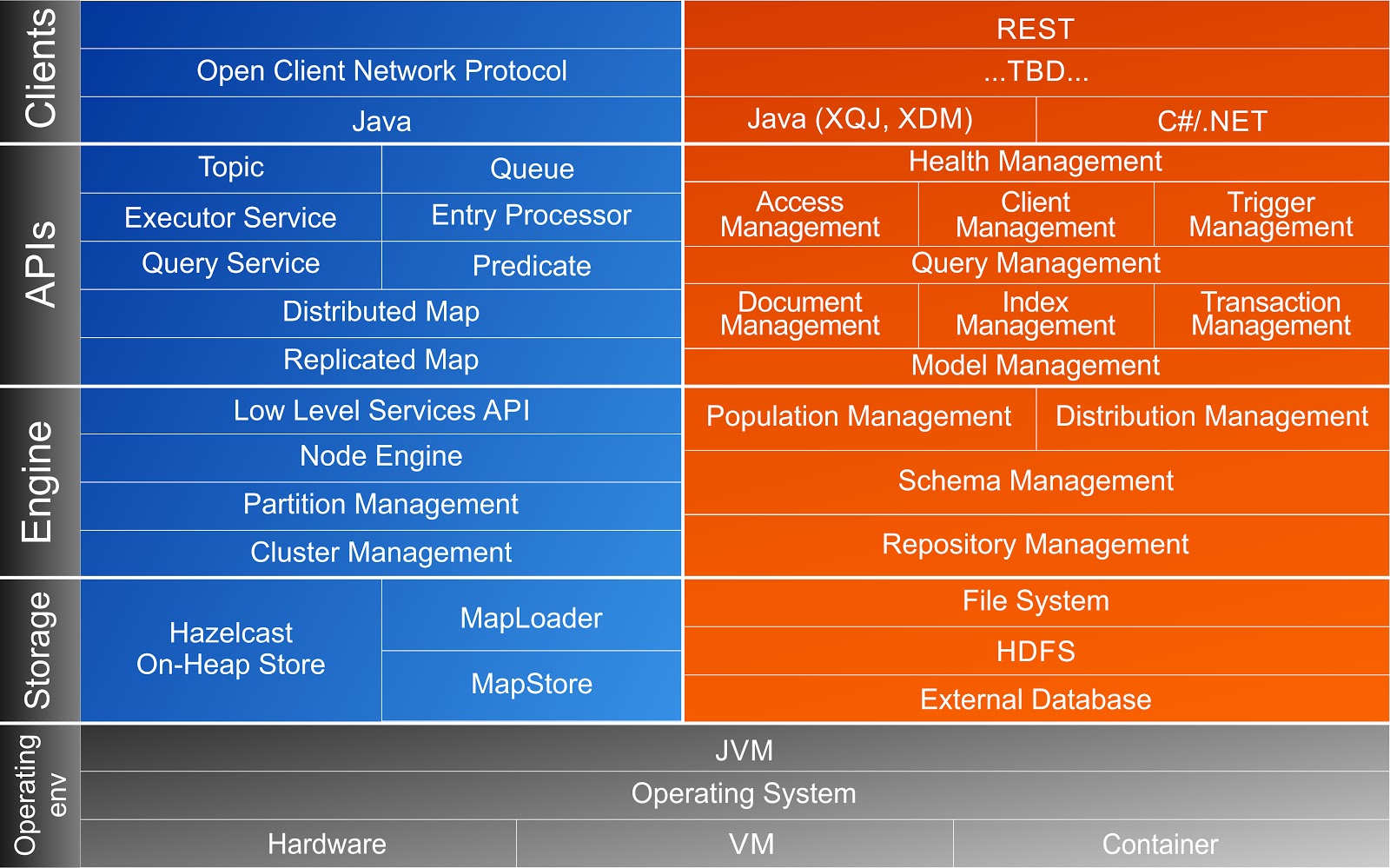
I found that most of the collected requirements could be satisfied with distributed data structures and mechanisms provided by Hazelcast IMDG. The layers diagram below (the left and bottom part of it were shamelessly stolen from the Hazelcast site) presenting how Hazelcast IMDG features are used in Bagri DB.

Repository Management with Hazelcast IMDG Clusters
A database server usually has many schemas or databases and they all are accessible by database clients at the same time. How can we achieve the same with Hazelcast? In Bagri, each database schema ends up in its own Hazelcast cluster– deployed independently of other schemas. The schema can be deployed on one or many nodes, and vice versa, one Bagri server can have many schemas deployed on it simultaneously. Thanks to Hazelcast which allows nodes from different clusters to be working in the same JVM. This way every schema has its own resource (thread) pool and data from different schemas will never interfere. This also gives a possibility to activate and passivate schemas at any time without affecting other active schemas.
In addition to the usual servers on which schema nodes are deployed, Bagri also provides administrative servers that store information about all deployed nodes and schemas. Administrative servers are part of a special system cluster. All the usual servers are also connected to this system cluster, but as “light” members. Thus, system data for all servers and schemas are stored only on administrative servers, but ordinary servers can read this data from system caches when they need it. And, most importantly, from the administrative server, you can run tasks on all or on any server group. This is how Bagri performs centralized management of the schemas – deployment of schemes on new nodes, their activation and passivation, indexing of data, collecting various schema statistics and so on. The tasks are executed on nodes with help of the Distributed ExecutorService provided by Hazelcast in the way we need it, i.e. synchronously or asynchronously, reliably or not, depending on a particular case.
Distribution Management with Hazelcast Services SPI
Not all tasks can be performed using only the standard Hazelcast data structures. But, in addition to standard data structures, Hazelcast provides a low-level Services API, which we can use to develop our own distributed structures and get direct access to the components (RecordStore) which store the schema data. Sometimes this helps to maximize performance, for example, in operations that run from a thread assigned to partition containing data being processed.
When developing your database, you need to pay attention not only to how quickly the system saves and queries data, but also to ensure that the data is distributed evenly across the partitions of the scheme and that there are no distortions in the use of resources (threads, memory) by separate partitions, and you can get the distribution of data between partitions also easily through the Hazelcast API.
A Replicated Cache for Model Data Management
As it was mentioned above, we needed a very fast, very accessible cache for our model data, which contains the set of all XPath segments used in the current schema. Thus, the cached model data must be local on all schema nodes. We achieved this with the Replicated Map structure provided by Hazelcast. However, we can also use a regular (Distributed) Map structure with near-cache on top of it holding data in OBJECT format on all schema nodes. As the model data is quite static (only new XPaths are added, old ones are never changed or deleted) the second approach works equally well.
A Distributed Cache for Document Data Management
Any schema can contain any number of documents. Documents are included in collections and XQuery expressions are used to query data. It is essential to be able to process that great amounts of data in parallel. Thus, the data should be properly distributed between system nodes and, in order to increase performance (throughput), we just needed to add more nodes to the schema cluster. On the other hand, XQuery does query and match data belonging to a particular document, so it is beneficial to have all document data stored together. This is achieved with Data Affinity principles via an implementation of the PartitionAware interface provided by Hazelcast. The document data elements are stored in the cache based on keys which consisted of the parent document’s identifier and element’s path identifier, thus, all document data elements are stored on the same partition.
XQuery Processing with Distributed Custom Indices
So, we sliced and stored the data of processed documents into caches. Now we needed to process the XQuery expressions and return results. A simple XQuery statement looks like this:
declare namespace s="http://tpox-benchmark.com/security";
for $sec in collection("securities")/s:Security
where $sec/s:Symbol='IBM'
return
<print>The open price of the security "{$sec/s:Name/text()}" is {$sec/s:Price/s:PriceToday/s:Open/text()} dollars</print>
Here we just needed to get all documents from collection ‘securities’ which have a Symbol field equals to “IBM”, then get the Name and Price fields of the document and return them in the query result. To find the required documents, we can get from data cache all the elements with /s:Security/s:Symbol XPath, then take these ones where the element’s value is “IBM” and return their document keys. This works well, especially when there is a Hazelcast index built on a XPath field. But, if we have N documents in our collection, we still have to execute N comparisons. To further accelerate such a search, we can built our own index as a separate cache that uses pairs of path/value as keys pointing to the corresponding document identifiers. Thus, the search for indexed data now is just to get data from cache by key, what can be faster? Then pass the found documents to XQuery processor and it would do the rest. That type of custom index works well for equality comparison, but doesn’t help at all in the range search operations. This is where the Hazelcast Services API came to the rescue again and we able to implement our own distributed structure to handle the range indices efficiently.
Distributed Transactions via Documents Versioning
Hazelcast has an ability to perform cache operations transactionally. But this functionality is slightly limited: Hazelcast transactions are managed (started/committed/rolled back) from a single TransactionContext instance. This situation is hard to achieve in a Bagri context when transactions are managed via distributed execution tasks coming from the client side and any transaction can involve many documents that can also be part of different schema nodes. That is why Bagri uses a different transaction schema: it implements MVCC via Transaction objects stored in another distributed cache. The mechanism is very close to what is implemented in PostgreSQL: every Document has a version and start/finish transaction identifiers. The transaction object holds the transaction state (in progress, committed, rolled back). When a Transaction gets to state committed all Documents involved in the transaction are also considered to be committed.
Distributed Task execution with ExecutorService
The ExecutorService provided by the Hazelcast platform is the actual engine of Bagri’s solution. As it was mentioned above, all system management tasks are accomplished with help of this service. All document management and XQuery functionality is also done by means of execution tasks. Triggers fired before/after any document or transaction operation are also implemented as tasks run by ExecutorService. Synchronous trigger invocation before Document storage in DB allows us to perform some preliminary data validation or enrichment and reject document storage if it does not meet some conditions. Asynchronous triggers after Document stored allows to perform some extra work, like calculating aggregates or gathering statistics, without affecting the performance. Transaction-scope triggers allows to control transaction propagation in some special cases. Reliable ExecutorService recently added by Hazelcast team guarantees the task will be done even if there are some issues with the underlying cluster.
Access Management with Hazelcast Custom Credentials
Bagri DB is an open source project and anyone can use it free of charge. This decision slightly constrains the functionality we can use from the underlying Hazelcast platform. Hazelcast allows to register custom JAAS LoginModule implementation to handle any authentication and authorization requests, but this functionality is accessible in the Enterprise version only. However, it is still possible to pass custom Credentials implementation from client to server. Then it is not too complicated to implement the auth mechanism internally and just return valid/invalid credential params to the standard Hazelcast SecurityContext component depending on the auth result.
Communication with Clients via Result Queues
Ok, so we built our database. Now how should it be accessed by clients? Via JDBC driver, right? Well, as we do a NoSQL DB, our driver is also NoSQL. Bagri provides a XQJ (JSR-225) driver which allows to query documents from the database using the XQuery language. The physical connection between client and server is established using the Hazelcast client protocol. It allows concurrent use of a single physical connection by many logical clients. But, on the server side each client works in its own dedicated session. It is not a big deal to run an XQuery statement on the server side and return one or two resulting documents, but what can we do when query returns millions of documents? To prevent any resource exhaustion the Bagri server establishes a direct channel to asynchronously communicate query results back to the client. The channel is a Hazelcast Queue and the client can specify (in XQuery instructions) a batch size to use when it fetches results from the server. On the server side results are also produced lazily and then streamed to the channel only when client request a new page, so it is safe to run queries returning huge number of results.
Persistent Store for Processed Documents
Bagri DB keeps all data in memory. With high availability and fault tolerance mechanisms provided by Hazelcast (configurable number of synchronous/asynchronous backups) the system can be in active state for a long time. When an active schema runs out of resources it is easy to add new nodes to the schema cluster dynamically without any system downtime. But sometimes a schema has to be stopped for maintenance or deployment in a new data center or something similar. To prevent data loss, we must store documents in some persistent store and then load them back to the database. This is done via the MapLoader/MapStore interfaces provided by Hazelcast. There are various options of the persistent store implementation. The basic one allows Bagri DB to store processed documents in their original format (XML, JSON, or whatever) in the local file system or on a shared network drive. But there are other implementations of Bagri’s DocumentStore interface, which can be configured for any schema independently. The supporting project bagri-extensions contains several implementations of the DocumentStore interface, allowing to store to and load documents from HDFS, MongoDB or any RDBMS. So that is the story of how one choice led me to build a document database, Bagri, on Hazelcast IMDG,
In the latest Hazelcast IMDG release (3.8) a new distributed service was introduced: ScheduledExecutorService. You know what? I’m now thinking about a job scheduler in Bagri DB :).