
Director of Engineering
Jaromir wrote his first line of code when he was seven years old. Since then, he has been interested in understanding how systems work ‘under the hood,’ and enjoys blogging about it. Jaromir’s areas of specialty include: performance and stability tuning of JVM, garbage collectors, data grids, application servers and architecture and design of applications. He enjoys pushing systems towards their limits, sharpening his skills by exploring HotSpot source code, contributing to open source projects and arguing about development over a pint of beer.
View all blogs by the authorFeb 7, 2018
Use Hazelcast Jet to stream data from an IMap to a Kafka topic
Today I would like to show you how to use Hazelcast Jet to stream data from Hazelcast IMDG IMap to Apache Kafka. IMap is a distributed implementation of java.util.Map, it’s super-easy to use and it’s probably the most popular Hazelcast IMDG data structure.
This post assumes you have an existing application which uses IMap inside an embedded Hazelcast member and you would like to capture all data inserted into the IMap and push it into a Kafka topic. And obviously this won’t be a trivial one-off job, we want a continuous stream of changes from IMap to Kafka. This pattern is often referred as a Change Data Capture. One of the goals is to minimize impact on the existing application. And all this should not take more than 5 – 10 minutes.
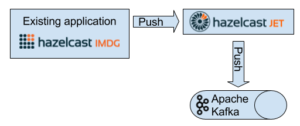
The high-level architecture looks like this: 
Existing Application
package com.hazelcast.jet.blog.imdg2kafka.cache;
import com.hazelcast.core.*;
import java.util.UUID;
import java.util.concurrent.ThreadLocalRandom;
public class StartCache {
private static final String MAP_NAME = "myMap";
private static final long KEY_COUNT = 10_000;
private static final long SLEEPING_TIME_MS = 1_000;
public static void main(String[] args) throws Exception {
HazelcastInstance instance = Hazelcast.newHazelcastInstance();
IMap<Long, String> map = instance.getMap(MAP_NAME);
for (;;) {
long key = ThreadLocalRandom.current().nextLong(KEY_COUNT);
map.put(key, UUID.randomUUID().toString());
Thread.sleep(SLEEPING_TIME_MS);
}
}
}
It’s very simple – it just starts a new Hazelcast IMDG instance, creates an IMap and start inserting UUID entries. It’s extremely trivial and it has nothing to do with Hazelcast Jet or Apache Kafka. The only dependency is Hazelcast IMDG, this is how your pom.xml could look like:
<dependencies>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>3.9.2</version>
</dependency>
</dependencies>
Nothing new or exciting so far – just the usual Hazelcast IMDG experience – a few lines code to start a new cluster, no server installation needed, no opinionated framework which wants to control your application. Let’s move on.
Apache Kafka Installation
In the next step we are going to download and start Apache Kafka. Once you have the archive with Kafka download & extracted then you have to start Apache Zookeeper:
$ ./bin/zookeeper-server-start.sh ./config/zookeeper.properties
When Zookeeper is running then you can start Apache Kafka:
/bin/kafka-server-start.sh config/server.properties
And finally you have to create a new topic Hazelcast Jet will push entries into:
./bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic myTopic
Hazelcast Jet Pipeline
Now comes to fun part: Use Hazelcast Jet to connect to your existing Hazelcast IMDG cluster with Apache Kafka. This can be a separate application and it the best Hazelcast tradition, it’s extremely simple! Check out the code:
package com.hazelcast.jet.blog.imdg2kafka.jetjob;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.jet.*;
import com.hazelcast.map.journal.EventJournalMapEvent;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.*;
public class StartIngestion {
private static final String MAP_NAME = "myMap";
public final static String TOPIC = "myTopic";
public final static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
JetInstance jetInstance = Jet.newJetInstance();
Pipeline pipeline = Pipeline.create();
//Let’s use the default client config. You could also configure IPs of your remote IMDG cluster
ClientConfig clientConfig = new ClientConfig();
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, LongSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pipeline.drawFrom(Sources.remoteMapJournal(MAP_NAME, clientConfig, false))
.filter((e) -> e.getType() == EntryEventType.ADDED || e.getType() == EntryEventType.UPDATED)
.drainTo(KafkaSinks.kafka(props, TOPIC, EventJournalMapEvent::getKey, EventJournalMapEvent::getNewValue));
jetInstance.newJob(pipeline).join();
}
}
Most of the code is actually related to Apache Kafka client configuration. This piece of code will run with just this dependency:
<dependencies>
<dependency>
<groupId>com.hazelcast.jet</groupId>
<artifactId>hazelcast-jet-kafka</artifactId>
<version>0.5.1</version>
</dependency>
</dependencies>
It also transitively fetches the Hazelcast Jet core and Kafka client libraries.
The Java code above:
- Creates a new Jet data pipeline
- Uses Hazelcast IMDG IMap as a source
- Applies a filter as we are only interested in newly added or modified entries
- Uses Kafka as a sink
At this point you are almost done. There is just one last bit: You have to tell to the existing application to maintain a log with IMap mutation events so the Jet pipeline can read from it.
This is the only change you have to do in the existing application and it turns out to be a trivial configuration-only change. You have to add to your IMDG configuration XML (hazelcast.xml) this snippet:
<event-journal>
<mapName>myMap</mapName>
</event-journal>
Now you can restart your Existing application to apply the new configuration, start the Jet pipeline and you are done! Hazelcast Jet will read mutation events from remote IMap event log and push them into Apache Kafka. You can easily validate it’s working with topic consumer distributed along with Apache Kafka:
./bin/kafka-simple-consumer-shell.sh –topic myTopic –broker-list localhost:9092
It creates a consumer and subscribe it to the topic Hazelcast Jet is pushing records into. If everything is working fine then you should see new entries every few seconds:
0102aced-a833-450d-a859-f881a0ce30bc 830200ef-6cc8-4789-910c-0899e1417de2 ebc5e3b3-7c57-4a82-8689-2c6641ecbbd1 aa173945-2e7a-404c-9234-7de2881ffd2b 0169ec70-f348-4554-b4ff-6c82b983a2c9
Summary
And that’s all folks. It took just a few minutes to push events from your existing application into Apache Kafka. This shows the simplicity of Hazelcast Jet – it can be easily embedded inside your application, it does not require you to maintain a separate server. It also offers an easy-to-learn API and as always with Hazelcast – it’s simple to scale it out!
In the next blogpost I’ll show how to implement a similar pipeline, but reversed. We’ll be using Hazelcast Jet to push events from Apache Kafka to an IMap. While waiting for the next blogpost you can have a look at Hazelcast Jet code samples and demos. Happy Hazelcasting and Stay Tuned!

